はじめに
セーフィー株式会社 開発本部 第3開発部 AIVisionグループで画像認識AIの開発エンジニアをしている土井 慎也です。
今回は、前回の記事で題材にしたGradioを使用して動画から文字起こしを行うアプリを簡単に作ってみたいと思います。
ローカルでAIを動かしますが、GPUは不要です。
また、オフラインでも実行は可能なので、セキュリティー的にも安心です。
使うライブラリ
- gradio
- WEBフレームワーク
- 簡単にWeb UIが作れる
- faster-whisper
- 音声認識
- OpenAIのWhisperモデルを高速化したもの
- moviepy
- 動画編集
- 今回は動画から音声のみを抽出するために使用
環境構築
python環境
python3.8以上が実行可能な環境を用意します。
ライブラリインストール
pip install faster-whisper gradio moviepy
コード実装
動画ファイルから音声ファイルを作る
input_video.mp4から音声のみ取り出したtemp_audio.mp3を作成
from moviepy.editor import VideoFileClip video_path = "input_video.mp4" output_audio_path = "temp_audio.mp3" video = VideoFileClip(video_path) video.audio.write_audiofile(output_audio_path)
音声ファイルから文字起こしする
今回はCPUで推論を行うため、deviceはcpu、compute_typeはint8を指定
GPUの場合はcuda、compute_typeはfloat16
from faster_whisper import WhisperModel model = WhisperModel("large-v3", device="cpu", compute_type="int8") segments, info = model.transcribe( output_audio_path, beam_size=5, vad_filter=True, ) response = "" for segment in segments: response += "[%.2fs -> %.2fs] %s\n" % (segment.start, segment.end, segment.text) print(response)
Web UIを作る
入力は動画ファイル、出力はテキストを想定
import gradio as gr def main(video_path: str): return "" demo = gr.Interface(fn=main, inputs=gr.Video(), outputs="textarea") if __name__ == "__main__": demo.launch()
コードを組み合わせる(完成版)
from faster_whisper import WhisperModel from moviepy.editor import VideoFileClip import gradio as gr import os model = WhisperModel("large-v3", device="cpu", compute_type="int8") def video_to_audio(video_path: str, output_audio_path: str): video = VideoFileClip(video_path) video.audio.write_audiofile(output_audio_path) def audio_to_text(audio_path: str): segments, info = model.transcribe( audio_path, beam_size=5, vad_filter=True, without_timestamps=True, ) print( "Detected language '%s' with probability %f" % (info.language, info.language_probability) ) response = "" for segment in segments: response += "[%.2fs -> %.2fs] %s\n" % (segment.start, segment.end, segment.text) return response def main(video_path: str): output_audio_path = "temp_audio.mp3" video_to_audio(video_path, output_audio_path) response = audio_to_text(output_audio_path) os.remove(output_audio_path) return response demo = gr.Interface(fn=main, inputs=gr.Video(), outputs="textarea") if __name__ == "__main__": demo.launch()
実行
pythonで作成したソースコードファイルを実行してしばらくたつと、以下のように表示されるので、ブラウザでhttp://127.0.0.1:7860を開きます
$ python main.py Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
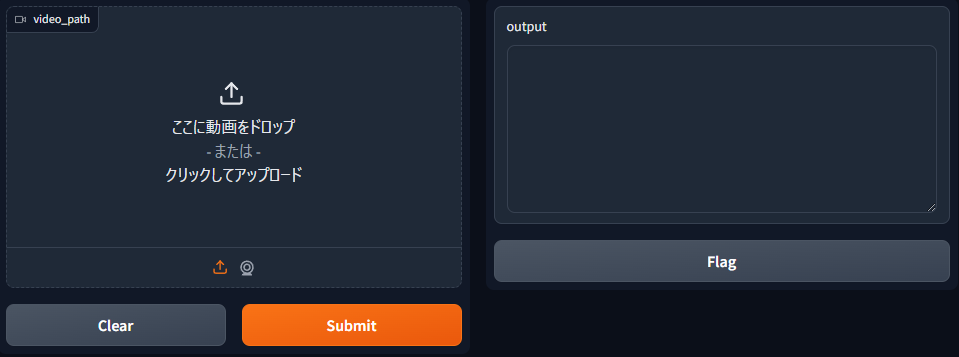
そうすると、このような画面が出るので、左のvideo_pathで動画を選択して、submitボタンを押すと文字起こしの処理が実行されます。
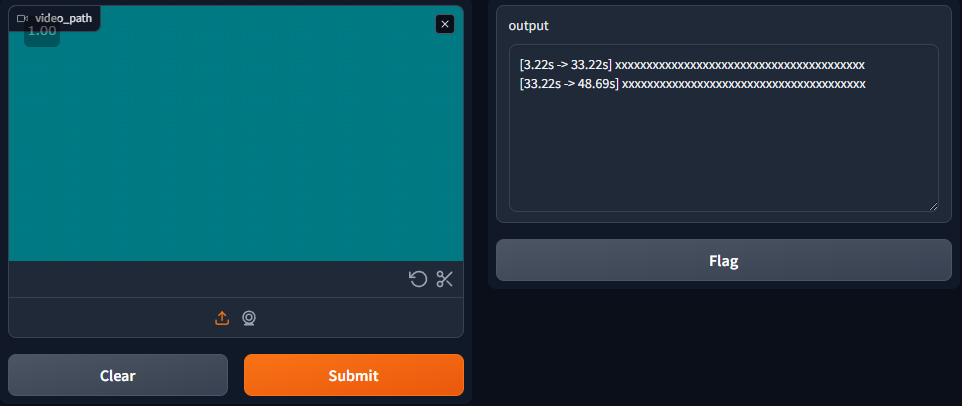
しばらく、そのまま待っていると、右のテキストエリアに結果が出力されます。
所感
簡単に実装できて実用的なアプリを考えたときに、whisperを使用した文字起こしアプリを選びましたが、思った以上に簡単に実装できました。
ここからさらに、LLMで要約したり、翻訳機能を使って多言語対応とかすると、さらに便利にできると思うので、近いうちにそういった改良もしてみたいと思います。
最後に
セーフィーではエンジニアを積極的に募集しています。気になる方はこちらをご覧ください!
https://safie.co.jp/teams/engineering/
カジュアル面談から受け付けておりますので、気軽に応募いただければと思います!
最後までお読みいただき、ありがとうございました。