この記事は Safie Engineers' Blog! Advent Calendar 23日目の記事です
はじめに
はじめまして、サーバーチームの城山です。 弊社の一部サービスで Kinesis Client Library(v2) for Python を利用しており、私なりに感じた躓きやすいポイントについてお話ししたいと思います。
Kinesis Client Library for Python とは
https://github.com/awslabs/amazon-kinesis-client-python
Kinesis Client Library for Python(以下KCL) は、kinesis data stream(以下KDS) からデータを取得し、処理するためのライブラリです。 Kinesis Client Library は Java で実装されており、MultiLangDaemon と言われる多言語インターフェースを利用することで、他の言語から利用することができ、Pythonでも利用することができます。
構成について
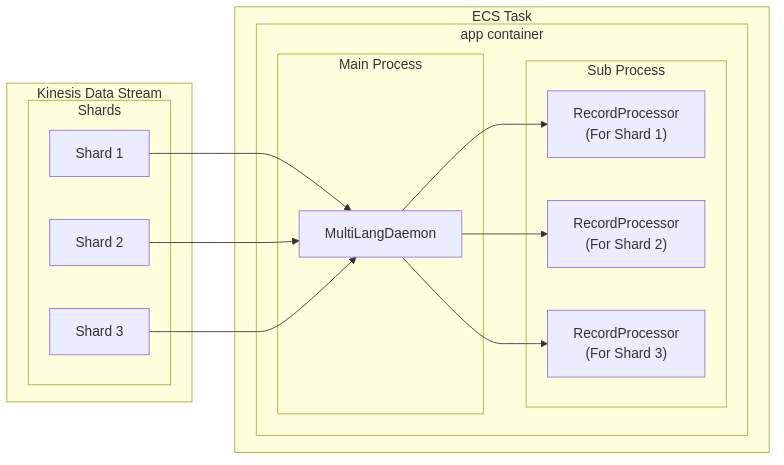
シャード数3、ECSタスク数1の場合の構成図です。 ※ 簡潔にするため、一部省略している箇所があります。
KDSに書き込まれたデータを、KCL の MultiLangDaemon が取得し、標準出力を介して、複数レコードが RecordProcessor(Pythonサブプロセス) に渡されます。 RecordProcessor では、主にDBへのデータ登録や、API連携等のビジネスロジックを実装しています。 また、KDSは複数のシャードに分かれており、RecordProcessor はシャード毎に1つずつ起動されます。 これにより、シャード単位での並列処理が可能となっています。
躓きやすいポイント
同一シャード内でのパーティションキー毎の処理遅延
1つのパーティションキーで大量にデータが登録された場合、同一シャード内の他のパーティションキーのデータが処理待ちとなり、処理が遅延する可能性があります。

例えば、上図のように、パーティションキーAのデータが大量に登録された場合、パーティションキーAのレコードを全て処理するまで、パーティションキーBのデータが処理待ちになるという状況です。
それに対し弊社では、RecordProcessor でパーティションキー毎に非同期処理を行うことで、特定パーティションキーの処理遅延が他のパーティションキーに影響を与えないようになっています。
また、queue.Queue を利用して、同一パーティションキー内でデータの順序を保持しつつ処理できるようにもなっています。
以下に一部抜粋してコード例を示します。(※ 実際のコードから一部簡略化しています)
def process_records(self, process_records_input: messages.ProcessRecordsInput): """ Called by a KCLProcess with a list of records to be processed and a checkpointer which accepts sequence numbers from the records to indicate where in the stream to checkpoint. Args: process_records_input (amazon_kclpy.messages.ProcessRecordsInput): the records, and metadata about the records. """ async def process_queue_record(record_queue: queue.Queue, partition_key: str): while not record_queue.empty(): record: messages.Record = record_queue.get() # ここからrecordの処理を行う async def process_records_in_parallel(records: list[messages.Record]): # partition key毎にqueueを用意し、recordをputする queues: dict[str, queue.Queue] = {} for r in records: if r.partition_key not in queues: queues[r.partition_key] = queue.Queue() queues[r.partition_key].put(r) # partition key毎に用意したqueueをevent loop内で並列に処理していく tasks = [] async with asyncio.TaskGroup() as tg: for key, q in queues.items(): tasks.append(tg.create_task(process_queue_record(record_queue=q, partition_key=key))) event_loop = asyncio.get_event_loop() event_loop.run_until_complete(process_records_in_parallel(process_records_input.records))
参考: awslabs amazon-kinesis-client-python (GitHub) / Apache License 2.0
重複レコードの制御
KCLのデプロイ、エラーによる予期せぬ終了、シャードのマージ、分割 等で、処理が途中で終了した場合、重複してデータが処理される可能性があります。
これに対し、データの生成元(弊社の場合はカメラデバイス)でデータの一意性を保証するためのIDを生成し付与してもらい、DB側でそのIDを保持し、重複レコードの制御が行われています。
以下に重複レコード制御に関する流れの例を示します。
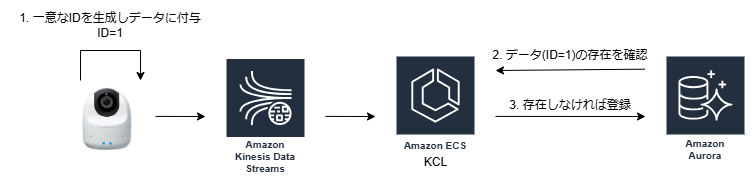
ECS Fargate task での RecordProcessor のログ連携
弊社では、アプリケーションのログドライバーとして主にAWS FireLensを利用し、ログを特定のサービスに連携しています。しかし、RecordProcessorはサブプロセスとして起動され、かつ標準出力がMultiLangDaemonとの通信に使用されるため、RecordProcessorのログを連携するには工夫が必要でした。この課題は、ログ出力先をMultiLangDaemonの標準出力先に変更することで解決されています。
具体的なコードは以下の通りです。(※ 実際の設定から一部簡略化しています)
import logging.config logging.config.dictConfig( { "version": 1, "handlers": { "file": { "class": "logging.FileHandler", "filename": "/proc/1/fd/1", # MultiLangDaemonの標準出力先 }, }, "loggers": { "app": { "level": "INFO", "handlers": ["file"], }, }, } )
タスク終了時の MultiLangDaemon のタイムアウトエラー
開発初期の頃、デプロイ時など古いタスクの終了時に、MultiLangDaemon 側でタイムアウトエラーが発生していました。
実際にタイムアウトが発生した際の MultiLangDaemon のログが以下です。
2024-01-25 06:28:02,986 [Thread-1] INFO s.a.k.multilang.MultiLangDaemon [NONE] - Process terminated, will initiate shutdown.
2024-01-25 06:28:02,917 [ShardRecordProcessor-0000] INFO s.a.kinesis.multilang.MessageWriter [NONE] - Writing ProcessRecordsMessage to child process for shard shardId-000000000012
at java.base/java.lang.Thread.run(Thread.java:829)
at software.amazon.kinesis.multilang.MultiLangDaemon.lambda$setupShutdownHook$0(MultiLangDaemon.java:183)
at java.base/java.util.concurrent.CompletableFuture.get(CompletableFuture.java:2027)
at java.base/java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1892)
java.util.concurrent.TimeoutException: null
2024-01-25 06:28:02,732 [Thread-1] ERROR s.a.k.multilang.MultiLangDaemon [NONE] - Encountered an error during shutdown.
この問題は、MultiLangDaemon が RecordProcessor に shutdown リクエストを送信し、その終了を待っている間にタイムアウトしていることが原因でした。これはKCLの設定値 shutdownGraceMillis を指定し、タイムアウト時間を調整することで解決されています。
shutdownGraceMillis = 10000
ローカル開発環境の構築
KCLは、DynamoDBとKinesis Data Streamに依存しています。KCLの設定でAWSのエンドポイントを指定できるため、AWSサービスをローカルでエミュレートできる LocalStack を利用して、AWS上のリソースを使用せず、ローカル開発環境が構築されています。
kinesisEndpoint = http://localhost:4566 dynamoDBEndpoint = http://localhost:4566
ちなみに、port 4566 は LocalStack のデフォルトのポート番号です。
まとめ
KCLを利用すること分散コンピューティングに関連する複雑なタスクを簡素化してくれるが、独自の対応が必要な部分があることがわかりました。
また、awsドキュメント等に記載がない設定値(kinesisEndpoint, dynamoDBEndpoint等)もあり、場合によってはソースコードを読むことも必要と感じました。