この記事は Safie Engineers' Blog! Advent Calendar 2023 の21日目の記事です。
はじめに
セーフィー株式会社で画像認識AIの開発エンジニアをしている木村(駿)です。主に、エッジAI搭載カメラで動作する人やモノを検出するアプリケーションの開発を行っています。
このAIカメラを使って、弊社では指定したエリアへの人の侵入を検知するサービスや混雑度合いを数値化するために滞留人数をカウントするサービスなどを提供しています。

これらのサービスが、必要な基準や要件を満たしているかどうかを確認するため、QA (Quarity Assureance) 評価を実施しています。具体的には、AIの検出性能や追跡性能のみを評価するのではなく、実際にユーザーが見る値(侵入検知のフラグやカウント数など)が正しく機能しているかを評価します。
このQA評価をするには評価用データ、つまりアノテーションされたデータが必要になりますが、動画のアノテーションデータの作成は非常に大変です。仮にFPS30の10分の動画に対してアノテーションデータを作ろうとすると、1フレームごとに5人映っていれば 30fps×600sec×5=90000個の矩形を手作業でつける必要があります。バリエーションを作ろうと思うと複数の動画のアノテーションデータが必要で、さらに大変です。
そこで、CGで映像を作成し、自動でアノテーションデータを作成できないかと考えました。 今回は、ゲームエンジンであるUnityを使ったCG映像の作成方法と、CGの人物に対して人検知を行った結果および簡易的なQA評価の結果をご紹介します。
利用したツール
Unity
- CG映像の作成にはUnityを利用しました。Unityは米国のUnity Technologiesが提供するゲームエンジンで、ゲームを簡単に作るための支援をしてくれる統合開発環境(IDE)です。3Dや2Dのグラフィックスを扱いやすくし、ゲームだけではなく映像の作成にも活用されています。
- 使用したUnityのエディタバージョン:2021.3.29f1(LTS)
Perception Package
- CGの人物に自動でアノテーションを付与するため、Unityが提供するPerception Packageを利用しました。
- Perception Packageは、画像認識モデルの訓練や検証に利用するための大規模なデータセットを生成するためのツールです。以下の動画ように、物体検出タスク向けのBounding Box 2D、セグメンテーションタスク向けのSemantic Segmentation や Instance Segmentation、姿勢推定タスク向けのKeypoint など様々なアノテーションデータを作成できます。今回は人検出なので、Bounding Box 2Dを利用します。
- 使用したバージョン:1.0.0

- CG人物の生成
- Perception Packageでは人物の生成が可能です。上記でアノテーションされている人物もアセットではなく生成された人物で、[ 性別、年齢、人種、身長、体型、服装 ] のパラメータをランダムに振って生成することができます。
- 生成した人物は、通常のUnityのアセットと同じようにC#Scriptやアニメーションなどのコンポーネントを付けることができるため、作成したい映像に合わせて動作させることができます。
CG映像の作成方法
次に、CG映像の作成方法を説明します。ここでは、弊社のAIカメラの機能であるエリア内に滞留している人数をカウントする機能のQA評価をするため、例としてスーパーのレジ待ちで並ぶお客さんを想定したCG映像を作成します。
背景を設定
まず、背景画像を設定します。今回は簡易的に静止画像を背景として、その前景に人を動かす仕様にしました。Unity上の設定方法としては、Camera Object の子オブジェクトとしてPlane Object を作成し、Plane Objectに背景画像を貼り付けます。そして、Camera Object と Plane Object の間で人を動かすことで、画像の前景として人が動く映像を作ります。
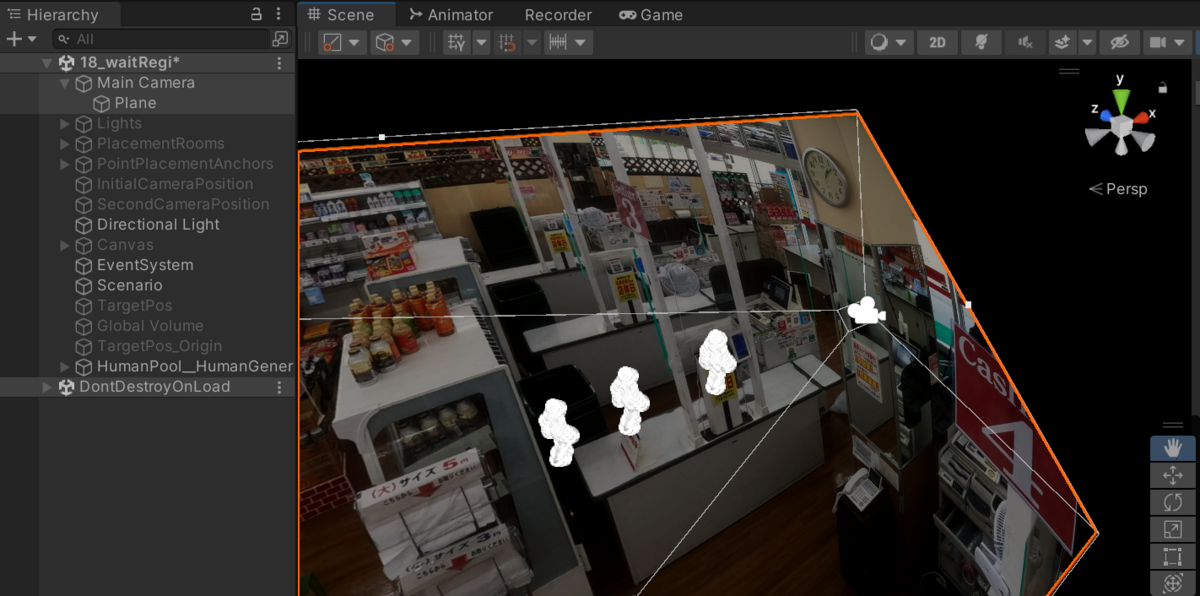 今回はこちらのスーパーのレジ付近の画像を背景に設定しました。人を左から右へ歩かせ、☆を先頭にして赤で囲んだ範囲に並ばせようと思います。
今回はこちらのスーパーのレジ付近の画像を背景に設定しました。人を左から右へ歩かせ、☆を先頭にして赤で囲んだ範囲に並ばせようと思います。

移動経路と動作を設定
人物の移動経路や動作を制御するアルゴリズムをC# で実装しました。
①
画面左側に人オブジェクトを生成し、上図の☆の位置を目標地点として左から右へ歩かせます。
以下のスクリプトで人オブジェクトを現在位置(transform.position)から目標地点(targetPosition)に向けたベクトル (moveDirection)方向へ移動させます。targetPositionはUnityのUIで入力できるよう、public 変数にしています。
public Vector3 targetPosition; public float moveSpeed; Vector3 moveDirection = targetPosition - transform.position; Vector3 deltaMovement = moveDirection.normalized * moveSpeed * Time.deltaTime; transform.position += deltaMovement;
②
目標地点に到達もしくは前に別の人がいたら立ち止まらせます。
以下のスクリプトで前方に人がいるかを判定します。前方のみの当たり判定を得るため、ColliderではなくRaycastを使用しました。
Ray ray = new Ray(transform.position, transform.forward); RaycastHit hit; hasFrontObject = false; if (Physics.Raycast(ray, out hit, 0.5f)) { hasFrontObject = true; }
目標地点に到達もしくは前にオブジェクトがあれば停止し、そうでなければ前進させます。
if (!hasReachedTarget) { Vector3 moveDirection = targetPosition - transform.position; // 目標地点に到達もしくは前にオブジェクトがあれば停止 if (moveDirection.magnitude > 0.5f && !hasFrontObject) if (moveDirection.magnitude <= 0.5f || hasFrontObject) { // 停止 transform.position = transform.position; hasReachedTarget = true; } else { // 前進 Vector3 deltaMovement = vec.normalized * moveSpeed * Time.deltaTime; transform.position += deltaMovement; } }
③
列に並んだ人オブジェクトは、しばらく時間が経過したら右を向いて再び歩きだしフレームアウトさせます。
if (!hasReachedTarget) { ~~~~ // 手順2の処理 ~~~~ } else { // 目標地点に達したので、一定時間が経つまで待ちます。 stayDuration += Time.deltaTime; if (stayDuration < stayTime) { // 一定時間経つまでその場で停止 Vector3 moveDirection = targetPosition - transform.position; } else { // 一定時間が経つと右に体の向きを変えて、再び前進 if (!hasRotated) { Vector3 exitDirection = transform.right; Quaternion rotation = Quaternion.LookRotation(exitDirection); transform.rotation = rotation; hasRotated = true; } Vector3 forwardDirection = transform.forward; walkForward(forwardDirection); } }
以上のアルゴリズムを用いて作成した映像がこちらです。描画されているバウンディングボックスは自動作成されたアノテーションです。
 期待通り列を形成してレジを待っている感じの動画が作られています。
期待通り列を形成してレジを待っている感じの動画が作られています。
人が宙に浮いている感は否めないですが、人検出モデルの性能を評価する分には問題なさそうです。
最後に、QA評価を行う前に、このCGの人物をAIが人として認識してくれるか確かめてみます。
人検知の確認
作成した映像に対してYolov5sで推論したところ、ちゃんと人として検出してくれました!
この生成と動作を繰り返す映像を作成すれば、レジに並んだ人数を正しくカウントできているかのQA評価ができそうです。

QA評価
上記の作成方法をベースにレジに並ぶ人数を変動させて30分ほどの映像を作成しました。この映像を用いて、カウントが正しくできているか評価します。カウントは人検出したBBOXの中心が10秒以上エリア内に留まった場合に行い、カウント数は1分ごとに集計しました。
以下のグラフが結果で、横軸は時間、縦軸が1分あたりのAIによるカウント数とGTです。GTはアノテーションデータを用いてカウントした数です。
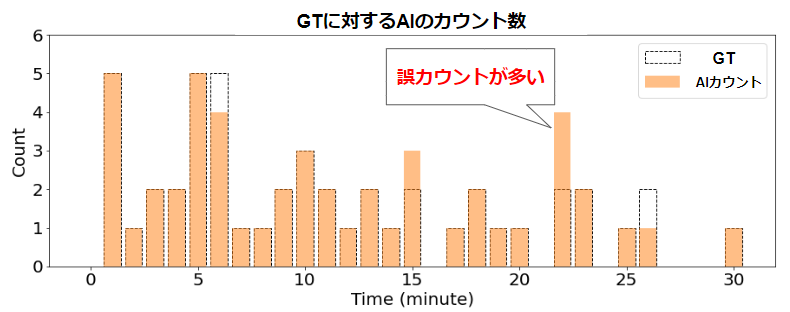 30分の映像の中で集計間隔ごとの誤カウント数が3、未カウント数が2と、かなり正確にカウントできていることが分かります。
30分の映像の中で集計間隔ごとの誤カウント数が3、未カウント数が2と、かなり正確にカウントできていることが分かります。
22分あたりの誤カウント+2の原因を映像から探ってみると、背景と同系色の服を着た人物の検出が途絶え、同じ人物を複数回カウントしていることが原因でした。実際のQA評価では背景やカメラアングル、人数などのパラメータを変えてバリエーションのあるデータセットで評価しているので、誤カウントや未カウントを起こしやすい環境や条件などをさらに詳しく分析できました。
まとめ
Unity Perception Packageを使って作成したCG映像でQA評価ができることが分かりました。
物体検出タスク以外にも、セグメンテーションや骨格推定などのタスクにも利用できますので、ぜひ使ってみてください。