はじめに
 こんにちは!2025年4月にセーフィーに新卒として入社した竹田です。私は25卒内定者として約10か月間、企画本部 AIソリューション部でインターンをしていました。ビジネス職として採用され、APIという単語も知らなかった私が、奮闘しながらシステム開発を行ったのでこのたび記事にさせていただくことにしました。
こんにちは!2025年4月にセーフィーに新卒として入社した竹田です。私は25卒内定者として約10か月間、企画本部 AIソリューション部でインターンをしていました。ビジネス職として採用され、APIという単語も知らなかった私が、奮闘しながらシステム開発を行ったのでこのたび記事にさせていただくことにしました。
今回は「映像×生成AI」を使ったオフィス5S管理ツールについて紹介させていただきます。
- はじめに
- なぜつくろうと思ったのか?~総務の課題見つけちゃったの巻~
- どんなものをつくったのか~血と汗と涙(?)の結晶の巻~
- どうやってつくったの?~いばらの道を振り返るの巻~
- 完成したツールのその後~つくってどうだったの?の巻~
- 今後の可能性~未来に羽ばたけの巻~
- 取り組みを終えて~ちょっと成長しましたの巻~
なぜつくろうと思ったのか?~総務の課題見つけちゃったの巻~
弊社は事業拡大に伴い社員数が急増し、オフィス環境の適切な管理が課題となっています。特に総務部門において、大きく2つの問題が顕在化してきていました。
まず第一に、社員数の増加に比例して総務部門の業務負担が著しく増大していたことです。日々のオフィス巡回、整理整頓の確認、備品管理など、5S(整理・整頓・清掃・清潔・躾)に関わる業務量が従来の管理体制では対応しきれない状況となっていました。
第二に、オフィスの拡張に伴い設置された多数の防犯カメラからの映像確認作業が煩雑化してきたことです。複数フロアに渡る数十台のカメラ映像を目視で確認する作業は、人的リソースの観点から非効率であり、重要な異常を見落とすリスクも高まっていました。
現状のオペレーションと課題に関する詳細を以下の図に示します。
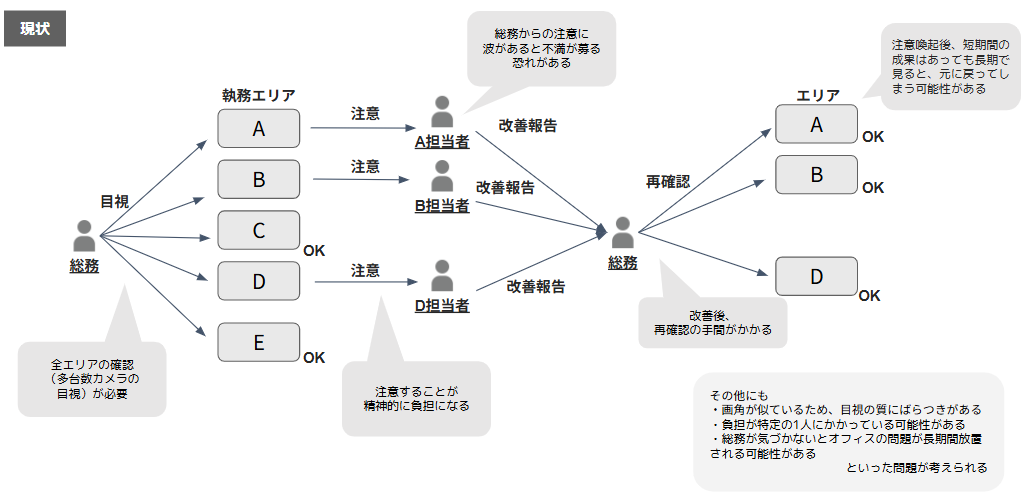 このような状況を打開するため、LLM(大規模言語モデル)の活用が最適であると判断しました。LLMを活用することでカメラ映像からの環境異常の自動検出だけでなく、状況に応じた改善提案の生成など、従来のオフィス管理で顕在化していた負担を軽減できると考えたからです。
このような状況を打開するため、LLM(大規模言語モデル)の活用が最適であると判断しました。LLMを活用することでカメラ映像からの環境異常の自動検出だけでなく、状況に応じた改善提案の生成など、従来のオフィス管理で顕在化していた負担を軽減できると考えたからです。
上記の背景から、LLMを活用した効率的なオフィス5S管理ツールのシステム開発を行うことにしました。本ツールは総務部門の負担軽減と管理品質の向上を同時に実現することを目指しています。
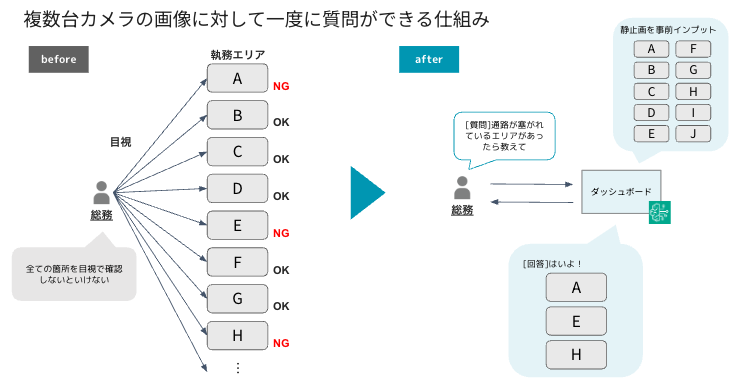 この時の構想としては上の図のような複数台のデバイスに対して一度に質問ができる仕組みがあれば便利そうだという構想を練っていました。質問に対して見る必要のあるデバイスの情報のみが結果として返ってくれば、大幅に目視の手間を省けると考えました。
この時の構想としては上の図のような複数台のデバイスに対して一度に質問ができる仕組みがあれば便利そうだという構想を練っていました。質問に対して見る必要のあるデバイスの情報のみが結果として返ってくれば、大幅に目視の手間を省けると考えました。
どんなものをつくったのか~血と汗と涙(?)の結晶の巻~
早速ですが、最終的に作ったツールを紹介させてください。
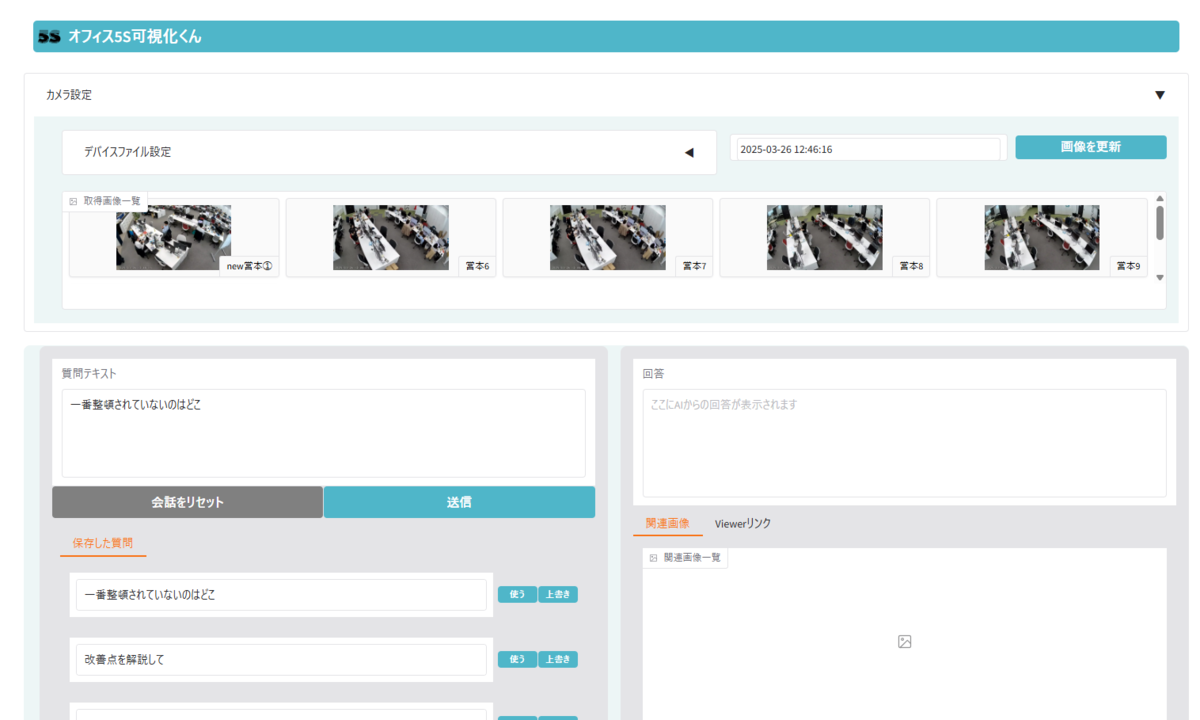 ツールの機能は大きく3つあります。
ツールの機能は大きく3つあります。
1.分析するデバイス(カメラ)を選択する機能
どのデバイスから情報を取得するかを決めるために設定ファイル(簡単なJSONファイル)を用いています。この設定ファイルには『デバイスID』と『エリア名』が書かれていて、このファイルを編集するだけで、別のデバイスから情報を取得する場合でも簡単に切り替えることができます。
2.分析に使う画像を更新する機能
分析にリアルタイムの画像を使用したい場合、「画像を更新」ボタンを押すだけで5S分析用の最新静止画を自動的に取得できます。取得した画像は「取得画像一覧」に表示されるため、簡単に確認できます。
3.テキストで質問を送って回答を取得できる機能
この機能では、利用者の目的に合わせてテキストで質問ができます。質問に対しては、該当するデバイスの画像、AIによる解説、該当の映像までのリンクが表示されます。視覚情報とAIの説明で、効率よく問題を解決できるという特徴があります。
どうやってつくったの?~いばらの道を振り返るの巻~
さて、ここからは実際に作っていく過程をお話しできればと思います。
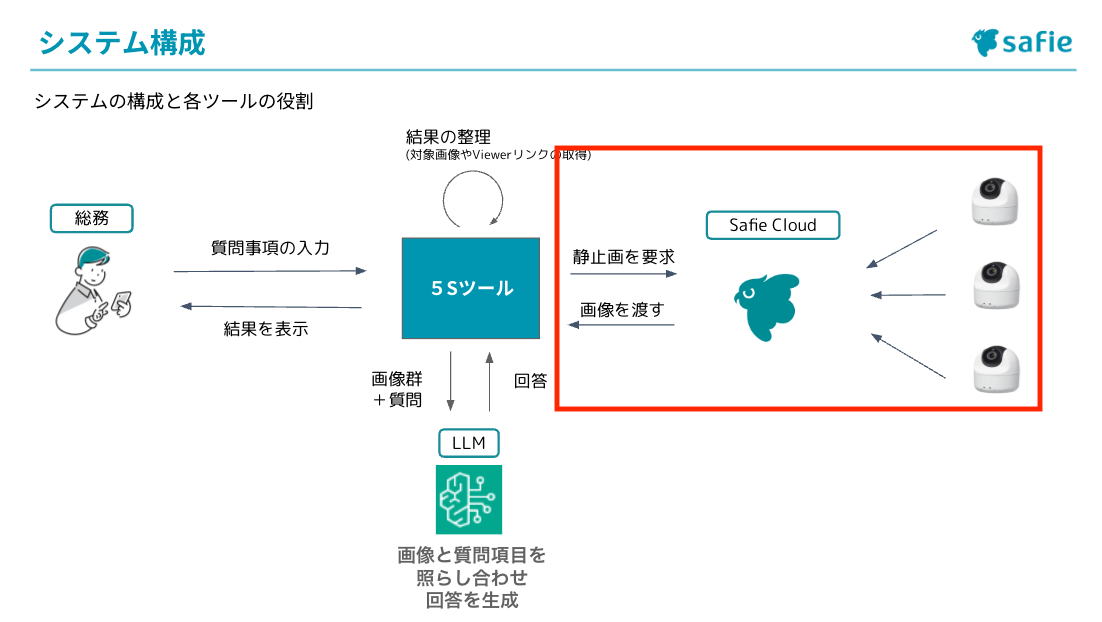
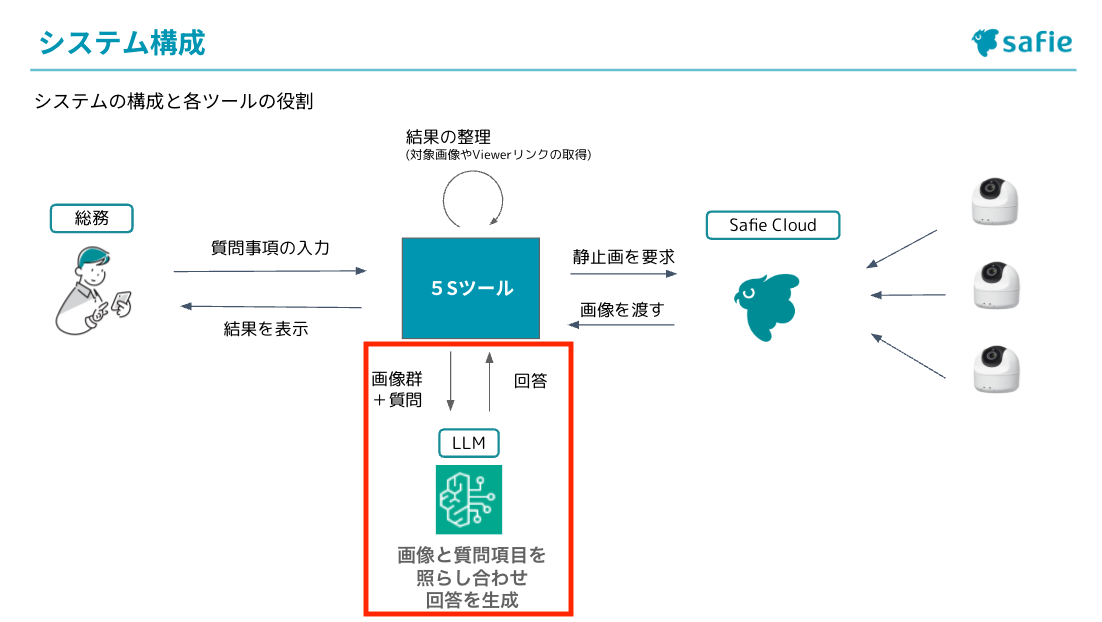
システムの構成は以下のようになっています。
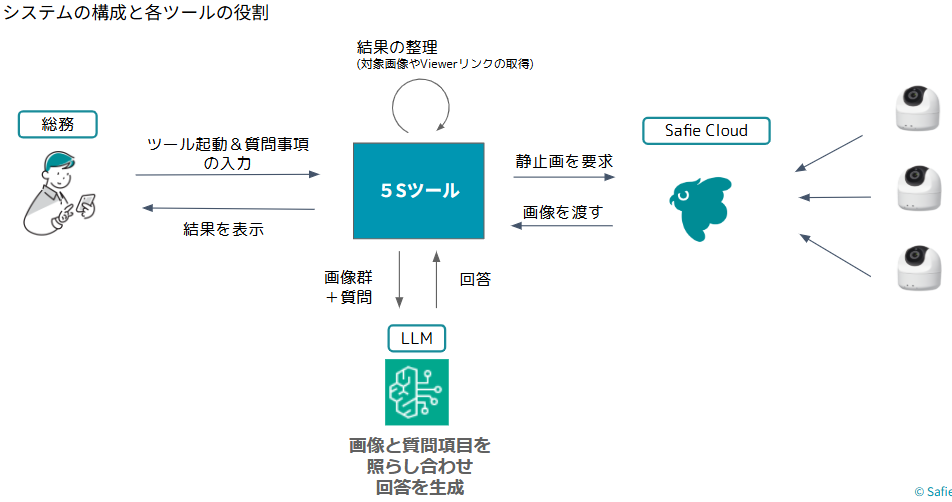 このシステムは、利用者が入力した質問と各デバイスから取得した静止画を組み合わせてLLMに送信します。LLMはその情報を処理して回答を生成し、システムはその回答をツールの仕様に合わせて整理してから利用者に表示します。つまり、質問と画像を入力として受け取り、AIが処理した結果を見やすい形で出力する仕組みになっています。
このシステムは、利用者が入力した質問と各デバイスから取得した静止画を組み合わせてLLMに送信します。LLMはその情報を処理して回答を生成し、システムはその回答をツールの仕様に合わせて整理してから利用者に表示します。つまり、質問と画像を入力として受け取り、AIが処理した結果を見やすい形で出力する仕組みになっています。
こちらはGradioで実装しており、作成時点ではローカル環境で実行しています。
ここから実際に作成した手順に合わせて、工程を説明します。
- ステップ① 静止画取得
- ①-1 設定ファイルからデバイス情報を取得する
- ①-2 Safie APIからの画像取得
- ①-3 画像の保存と更新
- ステップ② LLMのBot作成
- ステップ③ LLMのAPI連携
- ステップ④ 画面作成(UI作成)
ここでは、各ステップに対して、前半が作業内容(🧑💻)、後半が私の感想(🗣️)という構成で書かせていただいています。
ステップ① 静止画取得
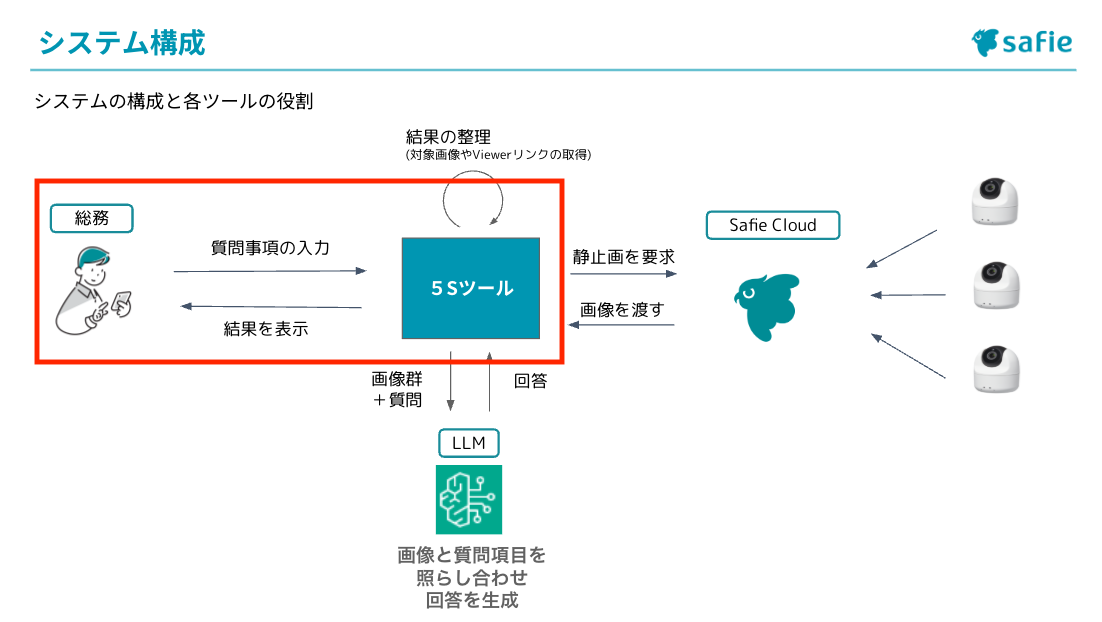
まず初めに取り組んだのは各カメラから分析用の静止画を取得する作業です。
システム構成図のこの部分ですね。
 こちらは3Stepで作業を実施しました。
こちらは3Stepで作業を実施しました。
①-1:設定ファイルからデバイス情報を取得する
🧑💻)どのカメラから情報を取得するかは、管理者が変更しやすいように、JSON形式の設定ファイルで管理するようにしました。このファイルには、各カメラのIDと、オフィス内のどのエリアを映しているかの名前が紐付けられています。アプリ起動時や設定変更時にこのファイルを読み込み、連携するカメラを特定します。
書いたコードがこちら
def load_device_info_from_json(): """ デバイスファイルからデバイスID、エリア名のリストを読み込む関数 Returns: list: (device_id, area_name) のタプルのリスト。エラー時は空リストを返す """ try: config = load_config() with open(config["device_file_path"], 'r', encoding='utf-8') as file: devices = json.load(file) # データ構造が期待通りかチェック if not isinstance(devices, list): raise ValueError("JSONデータがリストではありません") device_info = [ (device['device_id'], device['area_name']) for device in devices if 'device_id' in device and 'area_name' in device ] return device_info
jsonファイルの中身は以下のような形式になっております
[ { "device_id": "xxxx", "area_name": "yyyy" }, { "device_id": "zzzz", "area_name": "wwww" } ]
🗣️)ここまでは順調な滑り出しで、コードを書くのは初めてでしたが楽しんでできていました。
「よっしゃーこのままいくぞー」と意気込んでいたのもつかの間、トントン拍子にことが進むわけではありませんでした。
①-2:Safie APIからの画像取得
🧑💻)実際にカメラの画像を取得する部分の作成を行いました。ここでは、Safie APIを用いて、各カメラの静止画を指定した時刻でリクエストします。取得した画像データに対して、どのカメラのものか、どのエリアのものかといった情報も付与し、一緒に保存します。静止画取得の詳細はこちらのリファレンスをご参考ください。
静止画取得のSafie APIは以前に勉強会でコードを見たことがあったので、それを参考に書き始めました。「リファレンスを見て1から書く」ではなかったので、完全停止することなく進めることができました。
🗣️)ここでは忍耐力が大切だと気付きました。最初は意図したタイミングで画像が取得できないことがありました。画像らしきものは入っていたものの、No Imageといった形で中身が空だったり、意図した時間と違う時間の画像が取れたりと苦戦しました。何度か繰り返すと取得自体は問題なくできたので、この時点でもまだ余裕な気持ちがありました。
①-3:画像の保存と更新
🧑💻)取得した画像は一時的にアプリ内に保存されるようにしました。これは「質問を送るたびに画像取得のAPIが走る」という不要なアクセスを減らし、サーバ側の負荷を軽くすることで、アプリケーションの応答性を向上させることが目的です。(リセットボタンを押すまでは、異なる質問を送っても同じ画像に対して分析が行われるようになっています)
とはいえ、リアルタイム画像を分析したいという要望もあると思うので、ユーザーの指示によって最新の情報に更新できる動作も加えました。
🗣️)ステップ①で最も大変だったのがこの①-3の部分です。
「画像を更新」ボタンを押してもエラーが返ってきたり、うまく画像が保存されていなかったりと、「どこが間違ってるんだこれ」と思うことも増えました。そこで調べながら試行錯誤を繰り返すうちに、プログラムの間違い探しと修正、いわゆるデバッグ作業をどのように行っていくかが分かってきました。一気にやろうとしすぎずに細かく分けて考える方が自分には合っているなと思いました。この時ほふく前進くらいのスピードですが、まだ前には進めている実感がありました。
ステップ②:LLMのBot作成
次にLLMとの連携の部分の説明をさせていただきます。システム構成の以下の部分です。
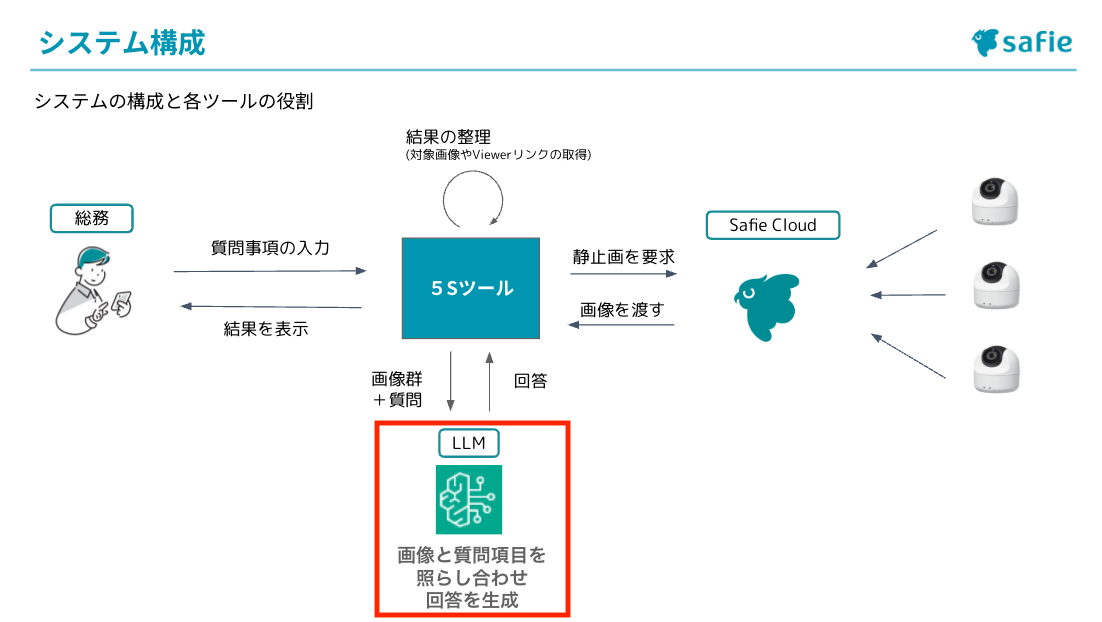 🧑💻)今回、質問文と画像を組み合わせて分析して回答を出してくれる存在としてLLMを使用しています。
🧑💻)今回、質問文と画像を組み合わせて分析して回答を出してくれる存在としてLLMを使用しています。
LLMはBedrockを使いました。こちらはAWSが提供する生成AIアプリケーション開発用のサービスです。主要なAI企業やAmazonが提供する高パフォーマンスな基盤モデルを、API経由で利用できます。
まず最初に行ったのは、今回私が使うツール専用のBotを作成することです。
メニューの「ボットコンソール」を開き、「ボットを新規作成」を選択します
 次にボットの基本情報を設定します。必要な情報は以下の3つ(ボット名、説明文、インストラクション)です。
次にボットの基本情報を設定します。必要な情報は以下の3つ(ボット名、説明文、インストラクション)です。
 今回はシンプルに、ボット名を「Office5S」、説明文を「オフィス5S可視化くん」、インストラクションには「あなたは5S分析のプロフェッショナルだ」といった内容を入れました。
今回はシンプルに、ボット名を「Office5S」、説明文を「オフィス5S可視化くん」、インストラクションには「あなたは5S分析のプロフェッショナルだ」といった内容を入れました。
 ボットを作成すると、作成したBotのAPIエンドポイント、APIキーを取得することができます。これはBotを使うために必要となる情報です。
ボットを作成すると、作成したBotのAPIエンドポイント、APIキーを取得することができます。これはBotを使うために必要となる情報です。
 最後にアクセスを許可するクライアントのオリジンを入力したら準備完了です!
最後にアクセスを許可するクライアントのオリジンを入力したら準備完了です!
ボットの作成が完了したら、それを動かすためのコードを書く必要があります。
🗣️)このBotをつくる作業は特段大変なことはなかったものの、プラグラムを書く上で重要なことを1つ学びました。それはBotのAPIエンドポイント、APIキーなどの重要な情報は直接書かないという点です。当たり前じゃんと思った方、その通りです。その通りなのですが、私はそんな当たり前を知らず、最初はプログラムにそのままAPIキーやエンドポイントを書いてしまっていました…。
現在はenvファイルに入れ、そのファイルを読み込むような仕様にしたのでご安心ください。(先ほどのSafie APIのキーもこちらに入っています)
ステップ③:LLMのAPI連携
🧑💻)Botを作成して次に行ったのが、Botと今回のツールをAPI連携することです。リファレンスはAWSが出している書き方をもとにつくった社内用のものを使いました。
 まず、いきなり本体ツールにコードを組み込むのではなく、API連携が成功しているかを試す軽めのテストをしました。テストに使用したコードはこちらです。
まず、いきなり本体ツールにコードを組み込むのではなく、API連携が成功しているかを試す軽めのテストをしました。テストに使用したコードはこちらです。
import boto3 from botocore.exceptions import ClientError # AWS認証情報(セキュリティ上の理由で環境変数やAWS CLI設定を推奨) AWS_ACCESS_KEY_ID = "XXXXXXXXXXXXXXXX" AWS_SECRET_ACCESS_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" AWS_REGION = "us-east-1" # 使用するリージョン # Bedrock Runtimeクライアントを作成 client = boto3.client( "bedrock-runtime", region_name=AWS_REGION, aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY, ) # 使用するモデルID(Claude 3 Haikuなど) model_id = "anthropic.claude-3-haiku-20240307-v1:0" # ユーザーメッセージを定義 user_message = "こんにちは、今日の天気はどうですか?" conversation = [ { "role": "user", "content": [{"text": user_message}], } ] try: # Converse APIを使用してメッセージを送信 response = client.converse( modelId=model_id, messages=conversation, inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9}, ) # conversation_idを取得して表示 conversation_id = response.get("conversationId") if conversation_id: print(f"Conversation ID: {conversation_id}") else: print("Conversation IDを取得できませんでした。") except (ClientError, Exception) as e: print(f"エラー: {e}")
ここで大体どんな関数を使い、どのような形でコードを書いていけばうまくAPIが動作するのかを把握することができました。そして、そのコードをもとに質問文と画像を同時にBedrockに投げて分析してもらえるような機能を実装しました。
🗣️)今回の取り組みで一番の山場がこのBedrockのAPI連携です。
あたかも簡単にできたみたいな書き方をしていますが、まずリファレンスを見て最初に思ったことは「何が書いてあるんだこれ」でした。Safie APIのリファレンスはこれまで何回か見たことがあり、意味が分からず固まるということがなかったのですが、今回のBedrockのAPIは初見では何が書いてあるのかほぼわかりませんでした。リファレンスを見て1からコードを書くということが初めてだったのです。そんな困ったときはまずChatGPT先生の出番です。「このリファレンス通りにコード書いて」と指示を送り、出てきたコードを実行してみましたが、結果はAPIエラーと返ってきてしまいました。
エラーを繰り返していくとさすがに自分が行き詰まっていることを感じました。その後開発の方に質問を投げましたが、いただいた回答は「リファレンス通りになっていない」というものでした。「え?これってリファレンスに沿えてないんだ」と思うと同時に今の理解では前進できないと感じ、トレーナーにヘルプを出しました。
一緒に考えてくださり、テスト用のコードをつくっていただきました。これがなければ前に進めていなかったと思います(感謝)
次の質問文と画像を同時にBedrockに投げて分析してもらえるような機能を実装していく過程も非常に大変でした。「一番整理されていないのはどこ?」といった質問を送って回答が返ってくるようになったので「できました!」とトレーナーに自信満々に見せたところ、画像が送られておらず質問に対してそれっぽい回答と解説をただ返してくれる謎ツールが誕生したのはいい思い出です。そんな紆余曲折あり、いろいろな人の力も貸していただき最大の山場を乗り越えることができました。
ステップ④:画面作成(UI作成)
🧑💻)UIの作成にはGradioを使いました。Gradioとは機械学習モデルのデモを行うWebアプリケーションを簡単に作ることができるPythonのライブラリです。詳細はこちらをご確認ください。
 まず、説明を割愛していましたが、事前に「こんな感じのものをつくりたい」という仕様書を作成していました。それを実際の利用者となる総務の方に見せて意見をいただき、画面構成のすり合わせを行いました。そこで完成した仕様書のイメージに沿うようにコードを書き画面を作成していきました。
まず、説明を割愛していましたが、事前に「こんな感じのものをつくりたい」という仕様書を作成していました。それを実際の利用者となる総務の方に見せて意見をいただき、画面構成のすり合わせを行いました。そこで完成した仕様書のイメージに沿うようにコードを書き画面を作成していきました。
いざ完成してみると「やっぱりこっちのほうがいいかも」としっくりこないことも多発し、最終的に5パターンほど検討して今の配置にたどり着きました。
以下が実際のコードの一部の例になります。より細かい部分は用意したCSSファイルを読み込ませて設定しました。
# メインコンテンツエリア with gr.Row(elem_classes="main-row"): # 左側カラム(質問入力エリア) with gr.Column(scale=3): with gr.Group(elem_classes="content-section"): # 質問入力セクション with gr.Group(): text_input = gr.Textbox( label="質問テキスト", placeholder="ここに質問を入力してください", lines=4.7, max_lines=20 ) with gr.Group(): with gr.Row(): reset_btn = gr.Button("会話をリセット", size="lg", elem_classes="custom-button half-width reset-button") analyze_btn = gr.Button("送信", size="lg", elem_classes="custom-button half-width")
🗣️)ここで面白かったのは、総務の方の「こんなのが欲しい」という意見に対して実現の可否も含めて調整していく過程です。「このやり方なら難しいけどこっちなら希望は叶えられるのでは?」と自分の中で選択肢を吟味して「それいいね」と言っていただいたときは嬉しかったのを覚えています。そしてイメージ通りの画面が作成できた時は非常に達成感がありました。
完成したツールのその後~つくってどうだったの?の巻~
作成したツールを総務の方に見せたところ、非常に良い反応をいただくことができました!
デモも試していただき、使いやすいという声もいただきました。現在はローカルではなく、セキュアな環境での運用に向けて開発の方を巻き込む動きをしていただいています。
今後の可能性~未来に羽ばたけの巻~
こちらのツールはLLM活用の最初の一歩としてシンプルな機能になっていますが、今後の可能性として幅広い展開が考えられます。今回はその中から2パターン紹介します。
- 5Sツールとしての強みを尖らせる方向
- 現在の評価は 5S項目のどこに問題があるのかわかりにくい仕様になっていますが、各5S項目を数値化して定量的な評価を導入すれば、より総務の方にとって使いやすいツールに改善できるのではと考えています。
- 既存のテキスト指示機能を応用する方向
- Safie Viewer上に質問用チャットを開けるボタンを設置することで、カメラ映像を目視する時間を減らし、効率的な映像分析が実現できるのではと考えています。
取り組みを終えて~ちょっと成長しましたの巻~
今回このツールの作成を振り返ってみると、最初に率直に思い浮かんだ感想は「難しかったなあ...」というものでした笑。
プログラミングやコーディングの知識がまったくのゼロからのスタートだったため、予想以上に多くの壁にぶつかり、挫折しそうになる場面がありました。特に初期段階では、専門用語の理解すらままならず、基本的な概念を把握するだけでも時間がかかってしまっていました。
しかし、日々の継続的な学習と実践を通じて、少しずつではありますが確実に進歩を感じられるようになりました。最初は断片的だった知識が次第につながり、システム全体の構造や各コンポーネントの関係性を理解できるようになっていきました。
特に学べたと思うのは、コードを単に「動かす」だけでなく、その「中身」や「仕組み」を理解できるようになったことです。なぜこの関数がここで必要なのか、このパラメータがどのような役割を果たしているのかといった点まで考えられるようになりました。
そして何より、「次はこんな機能が実装できるのではないか」、「このようなツールがあれば業務がもっと効率化できるだろう」といったアイデアが浮かんだときに、それを実現するための具体的な手段や方法をおぼろげながらも構想できるようになったことが、今回の取り組みで得られた最大の収穫だと感じています。
まだまだ学ぶべきことは山積みですが、今回の経験を足がかりに、今後も新たな挑戦へ挑んでいきたいと思います。